Generierung von Surrogate Keys im Informatica Mapping
In diesem Artikel möchte ich euch zeigen, wie man in einem Informatica Mapping Surrogate Keys erzeugen kann ohne dabei den Sequence Generator von Informatica oder eine Trigger-Sequence Kombination auf der Datenbank zu nutzen. Dieser Ansatz ist sehr performant und es entstehen auch keine Lücken in der ID Vergabe. Für mich ist dies die beste Lösung, um eine Primary Key Spalte zu füllen.
Ich möchte euch wie immer an einem kleinen Beispiel zeigen, wie das Informatica Mapping und die darin enthaltene Logik zum Erzeugen des Surrrogate Keys implementiert werden muss.
Mapping Übersicht
Um einen technischen Schlüssel in einem Informatica Mapping zu befüllen, sind nicht viele Transformationen erforderlich. Zwischen Quelle und Ziel ist lediglich eine Expression Transformation und ein zusätzlicher unconnected Lookup nötig.
Informatica PK ID erzeugen – Mapping
Unconnected Lookup
Der Unconnected Lookup wird verwendet, um die größte ID des Primärschlüssels aus der Zieltabelle zu extrahieren. Im SQL Override des Lookups fügt man dem Select ein zusätzliches Feld (z.B. DUMMY mit dem Wert „X“) zu der maximalen ID hinzu.
SELECT max(ID) as ID
, 'X' as DUMMY
FROM T_TGT_TABLE
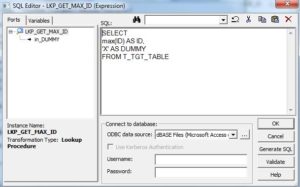
Informatica PK ID erzeugen – Lookup SQL Override
Die L-Ports des unconnected Lookup müssen immer in der gleichen Reihenfolge angegeben werden, wie diese im SQL-Override angegeben sind. Ein Aufruf eines unconnected Lookups per Funktion in einer Expression muss immer auch ein Input Attribut enthalten. Dieses wird verwendet, um per Lookup-Condition das Mapping zwischen Lookup-Cache und Lookup Eingang durchzuführen.
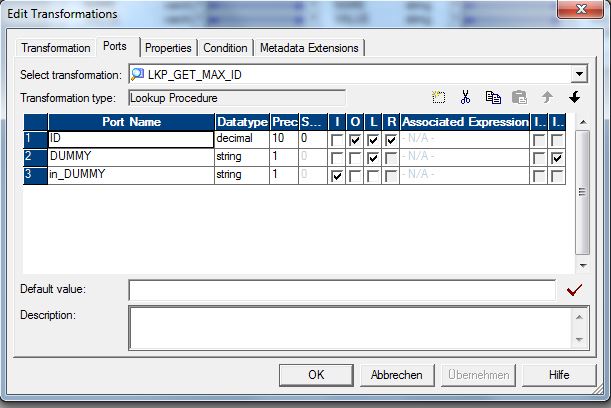
Informatica PK ID erzeugen – Lookup Ports
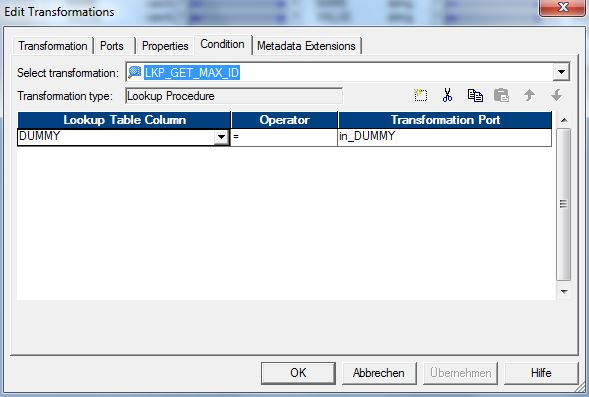
Informatica PK ID erzeugen – Lookup Condition
Expression Transformation
Um die Funktionsweise der verwendeten Variablen in der Expression Transformation erklären zu können, muss ich einen kleinen Exkurs in die Funktionsweise von Informatica machen.
Zur Laufzeit werden in einer Expression Transformation die Ports immer von oben nach unten prozessiert. Dabei verarbeitet Informatica zuerst alle Inputports, danach alle Variablen und anschließend alle Outputports. Da Informatica zeilenweise arbeitet, kann man sich zu nutzen machen, dass alle Variablen noch den Wert der vorherigen Zeile enthalten, bevor diese mit den Werten der aktuellen Zeile initialisiert werden. Hat also eine Variable z.B. in der vorherigen Zeile der Verarbeitung den Wert 5, so kann man auf diesen Wert in der nächsten Verabeitungszeile noch zugreifen, obwohl sie dort vielleicht mit dem Wert 6 belegt wird.
Die Expression Transformation in meinem Beispiel hat zwei Ports, die so aus der Quelle kommen und 1 zu 1 in das Ziel geladen werden. Zur Erzeugung des surrogate keys verwende ich 3 verschiedene Variablen (v_MAX_ID, v_NEW_ID und v_OLD_ID).
- v_MAX_ID enthält den Wert der maximalen ID aus der Zeiltabelle zu Laufzeitbegin.
- v_NEW_ID generiert den neuen surrogate key
- v_OLD_ID speichert den aktuellen Wert von v_NEW_ID, damit darauf in der nächsten Verarbeitungszeile darauf zugegriffen werden kann.
Weiterhin hat die Expression Transformation noch einen Outputport, der den generierten surrogate key in die Zieltabelle schreibt.
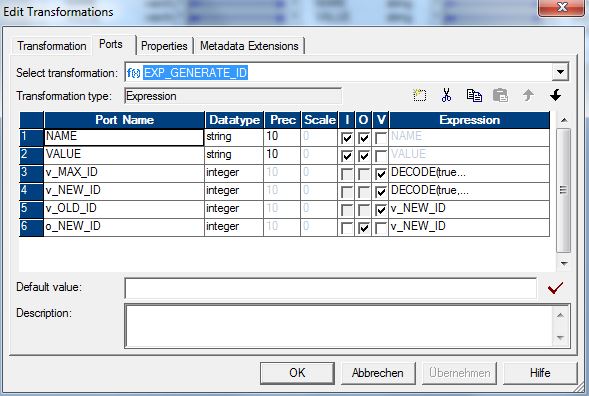
Informatica PK ID erzeugen – Expression
In der Expression der Variable v_MAX_ID wird überprüft, ob der unconnected Lookup einen Wert zurück liefert. Falls es sich um eine initiale Befüllung der Zeiltabelle handelt, kann der Lookup keine maximale ID liefern. In diesem Fall setze ich den Wert der Variable v_MAX_ID auf 0. Ansonsten wird der Wert gespeichert, der aus dem Lookup geliefert wird.
DECODE(true
, ISNULL(:LKP.LKP_GET_MAX_ID('X')), 0
, :LKP.LKP_GET_MAX_ID('X')
)
Die Generierung des surrogate keys erfolgt in der Expression der Variablen v_NEW_ID. Hier greife ich auf den surrogate key zu, der in der vorherigen Verarbeitungszeile generiert wurde. Ist dieser größer als die maximale ID aus dem Lookup und nicht leer, dann wird die ID um einen Zähler erhöht. Im anderen Fall handelt es sich um die erste Verarbeitungszeile und ich initialisiere die Variable v_NEW_ID, indem ich zum maximalen Wert aus dem unconnected Lookup 1 addiere.
DECODE(true
, v_OLD_ID > v_MAX_ID AND NOT ISNULL(v_OLD_ID), v_OLD_ID + 1
, v_MAX_ID + 1
)
Mehr ist nicht zu tun, um das gewünscht Ergebnis zu erzielen.
Ich hoffe, dass ich euch mit meinem Artikel weiterhelfen konnte. Falls ihr Fragen dazu habt, könnt ihr diese gerne im Kommentarbereich stellen und ich werde diese beantworten.